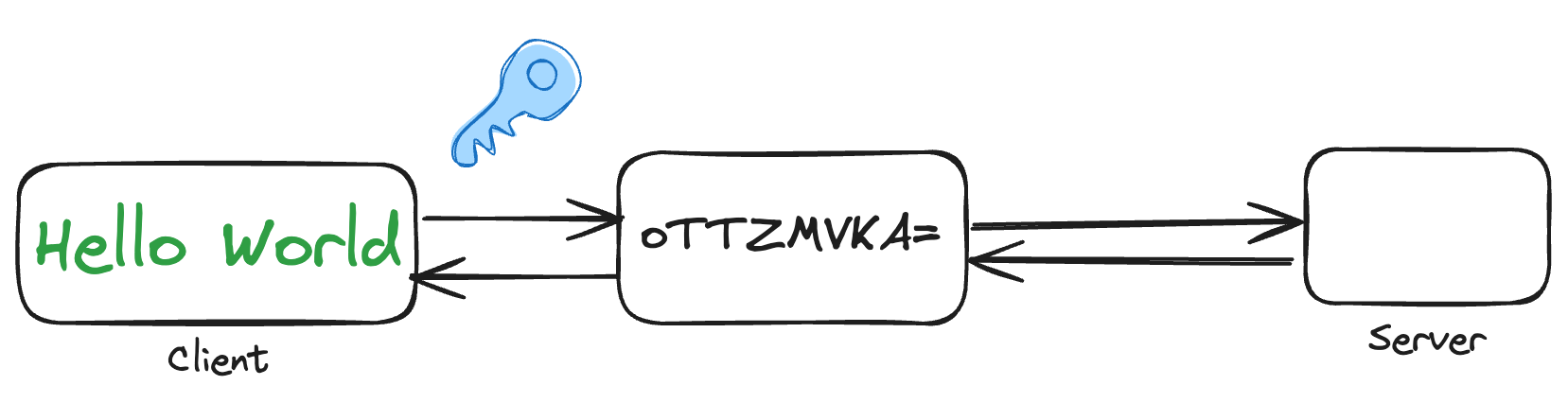
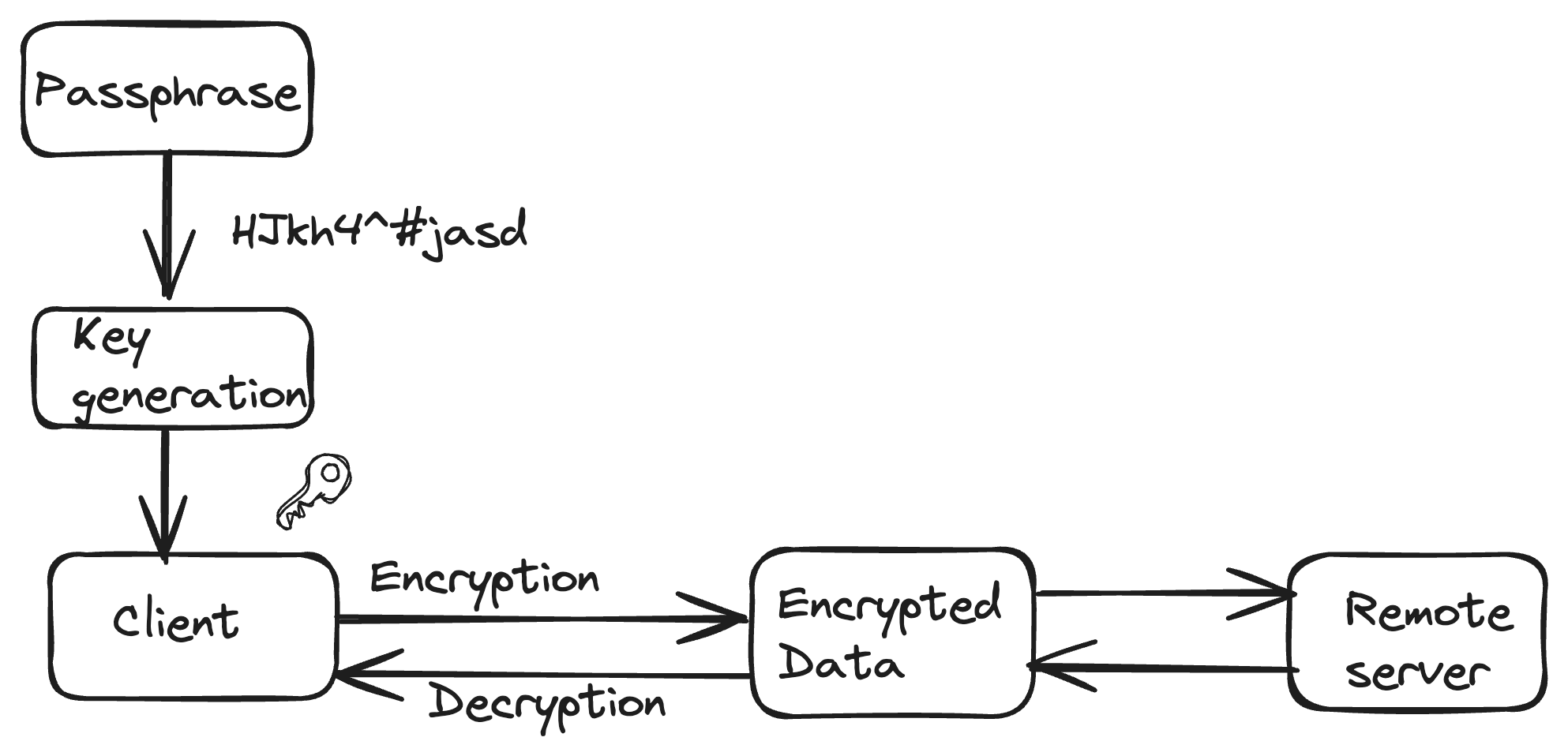
The most complicated and time-consuming parts of building a new storage system
are usually the edge cases and low-level details. Concurrency control,
consistency, handling faults, load balancing, that kind of thing. Almost every
mature storage system will have to grapple with all of these problems at one
point or another. For example, at a high level, load balancing hot partitions
across brokers in Kafka is not that different from load balancing hot shards in
MongoDB, but each system ends up re-implementing a custom load-balancing
solution instead of focusing on their differentiating value to end-developers.
This is one of the most confusing aspects of the modern data infrastructure
industry, why does every new system have to completely rebuild (not even
reinvent!) the wheel? Most of them decide to reimplement common processes and
components without substantially increasing the value gained from reimplementing
them. For instance, many database builders start from scratch when building
their own storage and query systems, but often merely emulate existing
solutions. These items usually take a massive undertaking just to get basic
features working, let alone correct.